



Go | Map 底层原理
Map 底层原理
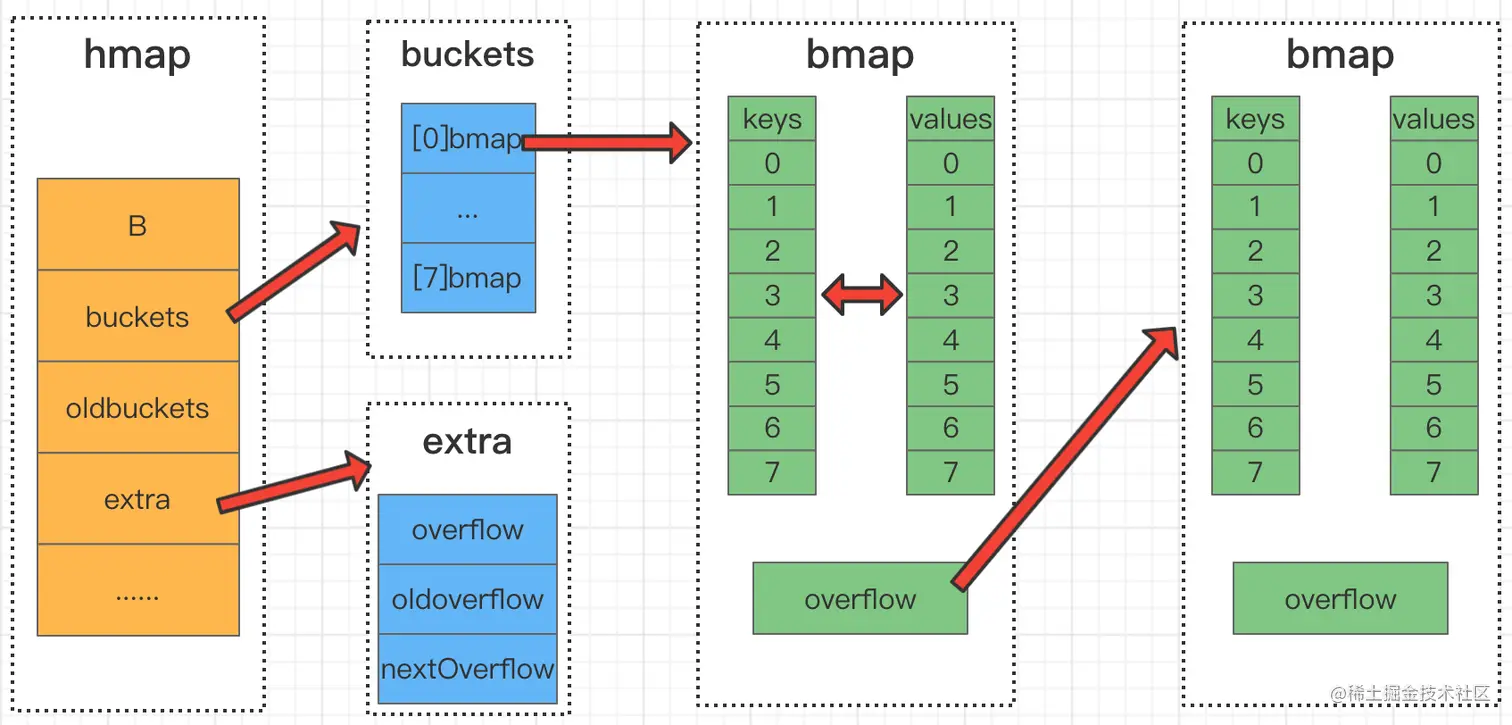
在go的map实现中,它的底层结构体是hmap,hmap里维护着若干个bucket数组 (即桶数组)。
Bucket数组中每个元素都是bmap结构,也即每个bucket都是bmap结构,每个桶中保存了8个kv对,如果8个满了,又来了一个key落在了这个桶里,会使用overflow连接下一个桶(溢出桶)。
GET获取数据
-
计算k4的hash值。由于当前主流机都是64位操作系统,所以计算结果有64个比特位
-
通过最后的“B”位来确定在哪号桶
-
根据k4对应的hash值前8位快速确定是在这个桶的哪个位置
-
对比key完整的hash是否匹配,如果匹配则获取对应value
-
如果都没有找到,就去连接的下一个溢出桶中找
PUT存放数据
-
通过key的hash值后“B”位确定是哪一个桶
-
遍历当前桶,通过key的tophash和hash值,防止key重复,然后找到第一个可以插入的位置,即空位置处存储数据。
-
如果当前桶元素已满,会通过overflow链接创建一个新的桶,来存储数据。
关于hash冲突:当两个不同的 key 落在同一个桶中,就是发生了哈希冲突。冲突的解决手段是采用链表法:在 桶 中,从前往后找到第一个空位进行插入。如果8个kv满了,那么当前桶就会连接到下一个溢出桶(bmap)。
扩容
由于map中不断的put和delete key
扩容实际上是一种整理,把后置位的数据整理到前面。这种情况下,元素会发生重排,但不会换桶。
2倍容量扩容 发生这种扩容时,元素会重排,可能会发生桶迁移
扩容的条件
装载因子是指当前map中,每个桶中的平均元素个数。
扩容条件1:**装载因子 > 6.5 **(源码中定义的)
扩容条件2: 溢出桶的数量过多
扩容时的细节
- 在我们的hmap结构中有一个oldbuckets吗,扩容刚发生时,会先将老数据存到这个里面。
- 每次对map进行删改操作时,会触发从oldbucket中迁移到bucket的操作【非一次性,分多次】
- 在扩容没有完全迁移完成之前,每次get或者put遍历数据时,都会先遍历oldbuckets,然后再遍历buckets。
Sync.Map 的底层原理
Go 的内建 map 是不支持并发写操作的,原因是 map 写操作不是并发安全的,当你尝试多个 Goroutine 操作同一个 map,会产生报错:fatal error: concurrent map writes。
因此官方另外引入了 sync.Map 来满足并发编程中的应用。
sync.Map 的数据结构如下
type Map struct {
// 加锁作用,保护 dirty 字段
mu Mutex
// 只读的数据,实际数据类型为 readOnly
read atomic.Value
// 最新写入的数据
dirty map[interface{}]*entry
// 计数器,每次需要读 dirty 则 +1
misses int
}
type readOnly struct {
// 内建 map
m map[interface{}]*entry
// 表示 dirty 里存在 read 里没有的 key,通过该字段决定是否加锁读 dirty
amended bool
}
sync.Map 的实现原理可概括为:
- 通过 read 和 dirty 两个字段将读写分离,读的数据存在只读字段 read 上,将最新写入的数据则存在 dirty 字段上
- 读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirty
- 读取 read 并不需要加锁,而读或写 dirty 都需要加锁
- 另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上
- 对于删除数据则直接通过标记来延迟删除
通过这种读写分离的设计,解决了并发情况的写入安全,又使读取速度在大部分情况可以接近内建 map,非常适合读多写少的情况。
sync.Map 还有一些其他方法:
Range:遍历所有键值对,参数是回调函数LoadOrStore:读取数据,若不存在则保存再读取


评论区