



k8s | 疑难问题总结
docker和k8s的区别及优势
Docker和K8s是两个不同的技术,docker是一种容器化技术,而K8s是一种容器编排技术,其主要的区别在于其使用场景和应用范围上。
Docker是一种开源的容器化平台,它可以将应用及其依赖打包到一个可移植的容器中,从而使应用可以在任何地方运行。真正实现“build once, run everywhere”
ETCD的 Raft 组件工作?
每个leader任期多长时间?
在ETCD中,Leader的任期(Term)是一个时间周期,在每个任期内,一个Leader被选举出来并负责处理客户端的读写请求。Leader任期的长度是一个超时时间,通常称为Leader任期超时(Leader Lease Timeout)。默认情况下,ETCD的Leader任期超时是1500毫秒。(通过设置--election-timeout参数来指定Leader任期超时时间)
当一个Follower节点发现自己已经有一个Leader,并且在Leader任期内没有收到Leader的心跳信号时,它会开始一个新的Leader选举过程,成为Candidate状态,并尝试在新的Leader任期内成为新的Leader。在选举过程中,节点会互相发送请求投票,最终获得大多数节点的支持成为新的Leader。
cloud-controller-manage ?
是 controller Manager 的一部分还是插件?
cloud-controller-manager是Kubernetes中Controller Manager的一部分,而不是插件,是其中一个特殊的Controller Manager,它主要用于管理与云平台相关的资源,比如Node、Route、LoadBalancer等。是需要额外安装的
kubernetes Pod 创建流程
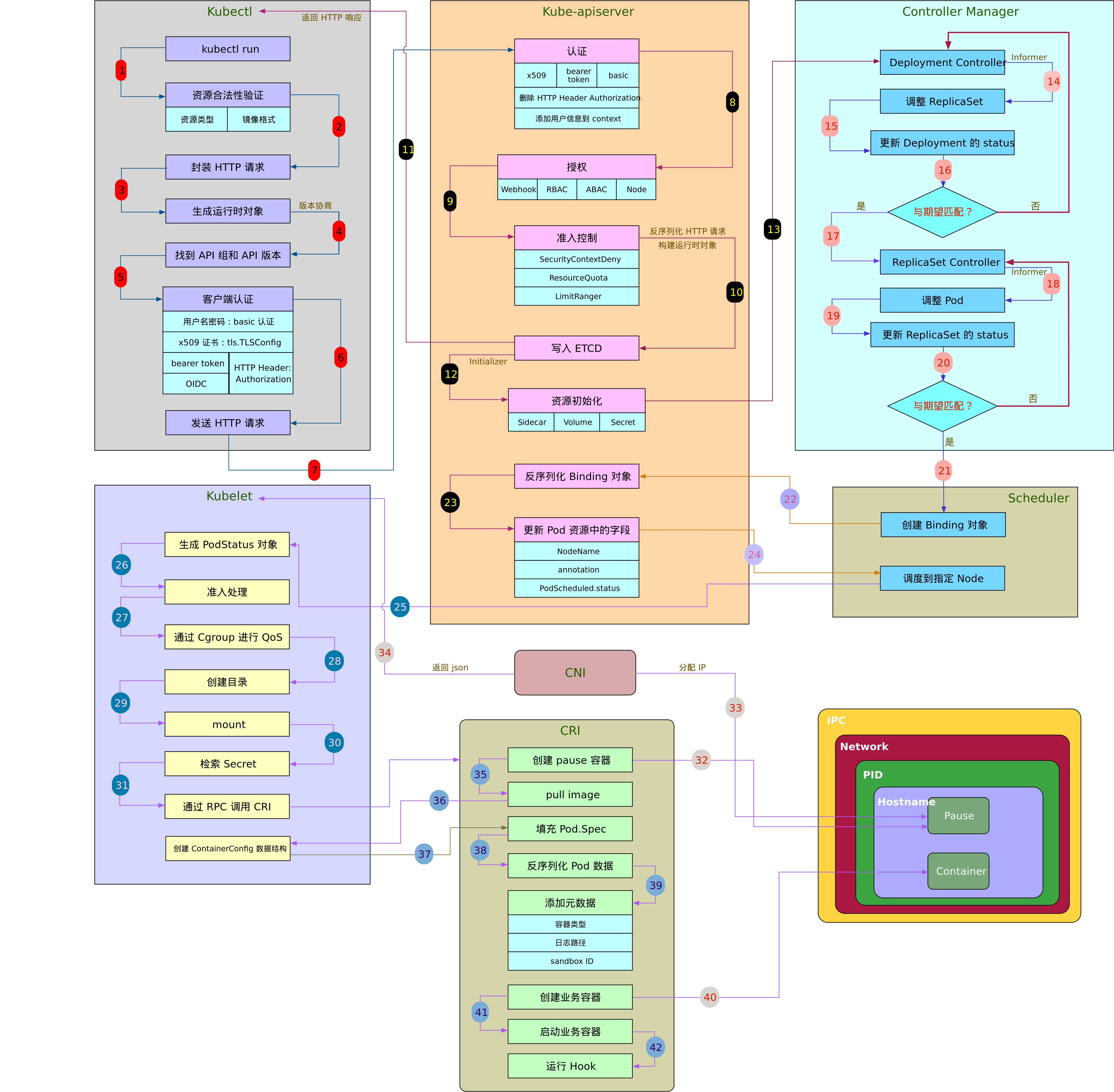
- 用户通过 kubectl 接口提交创建 pod 的 yaml文件,发起资源请求
- Apiserver 接收到用户请求,作出相应的认证,检查信息并将元信息存储到 etcd 中,创建Pod资源初始化
- APiserver将创建 pod 的消息通知到 kube-schedule, schedule 通过 list-watch 的监听机制 查看要创建的 pod 资源,之后触发调度流程进行调度
- controller Manager 根据一些调度算法,比如NodeSelector,优先级策略,节点亲和性,容忍性等,调度到合适的节点上
- kubelet 根据调度结果执行 pod 的创建操作,启动 容器运行时,将创建容器的任务交给 CRI。并将 pod 的相关信息存储到 etcd 中
- 如果属于某个 service的话,Endpoint 将 ip+port 添加到列表中
- kube-proxy 被通知 endpoint 更改,更新每个节点的 iptables 规则
参考:
Kubernetes创建Pod工作流程,看这篇就够了(详细)
kubernetes创建pod流程图 (简述)
Deployment 的 创建调度?
- 当创建一个
Deployment,它会创建一个与之关联的ReplicaSet,并根据 Deployment 的定义启动指定数量的 Pod 副本。 ReplicaSet监控Pod的状态,并确保始终有指定数量的Pod在运行。- 更新
Deployment的定义时(例如修改镜像版本或配置),Deployment会创建一个新的 ReplicaSet,并逐步替换旧的 ReplicaSet 中的 Pod,以实现无缝的滚动更新。
通过 Deployment 和 ReplicaSet 的配合,Kubernetes 可以保证应用程序的高可用性和弹性,同时支持灵活的滚动更新和回滚操作,就像一个招聘公司的招聘主管和执行团队一样,共同合作完成招聘和执行任务
pod的生命周期?
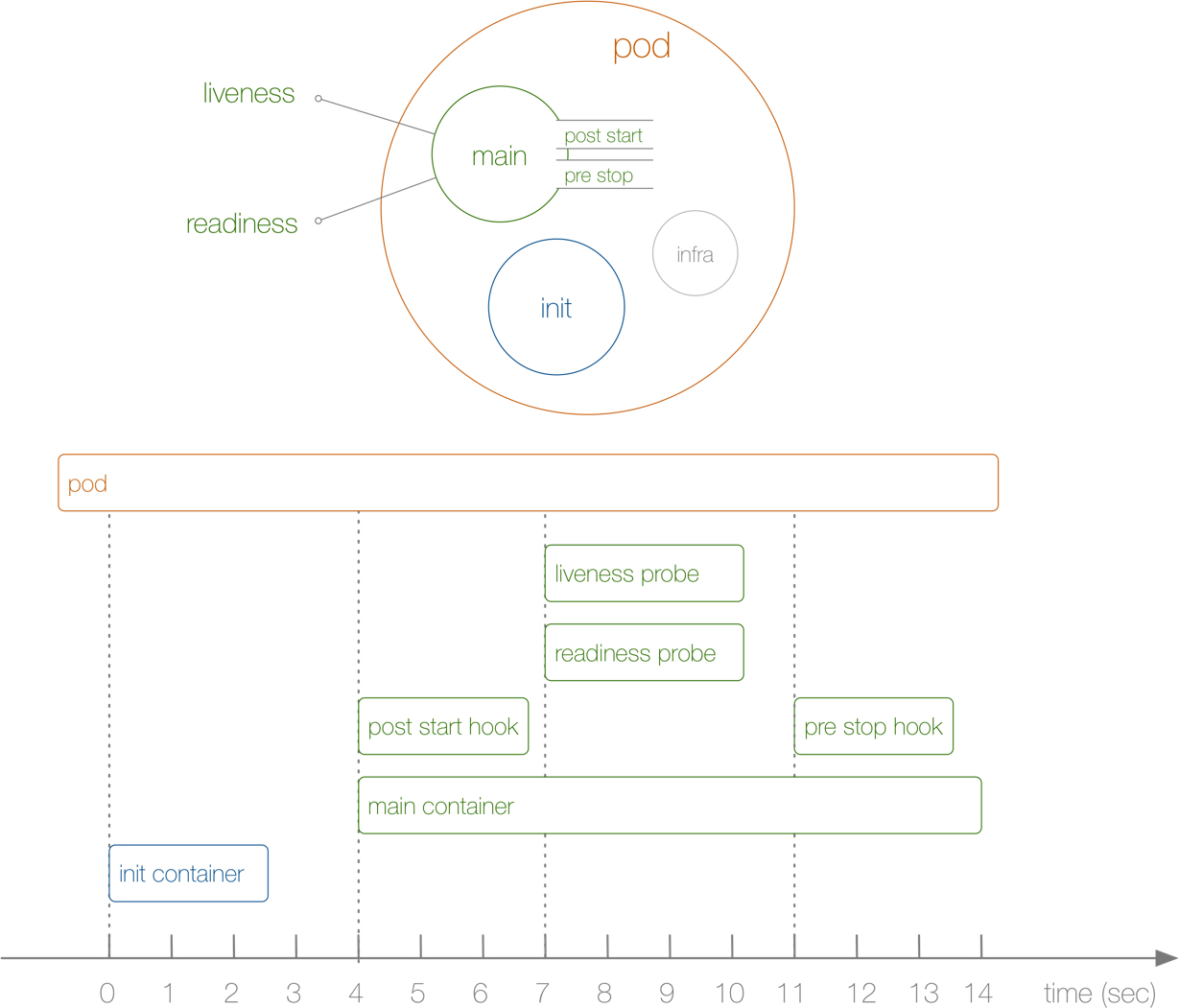
生命周期的整个过程包含 Init Container、Pod Hook、健康检查 三个主要部分
pod 的状态包括以下几个
- pending(挂起):还没有被调度到具体的节点,或者容器还在拉取
- Running(运行中):已经绑定节点,至少有一个容器正在运行或重启
- succeed(成功):所有容器都已成功终止
- failed(失败):至少有一个容器因为失败而终止
- unknown(未知):apiserver和kubelet通信失败
kubelet 的健康检查
两个探针的区别?检查不健康对pod怎么处理?
一句话:Liveness Probe 用来检测是否存活,Readiness Probe 用来检测是否准备好接受请求。存活不等于就绪
为什么需要健康检查
- 业务 CPU 占用率一直在限制值 附近,导致虽然Pod 业务在运行,但是已经得到更多的 CPU 时间片,无法正常处理业务请求或者处理业务非常慢
- 对于大型的应用启动时间较长,如果启动时就将 pod 标记为 Ready 并接收外部请求,将会有部分请求得到错误的返回
虽然业务进程处于运行状态,Pod 和容器也处于 Running 状态,业务可能正处于“启动中”或者出现“**资源不足”的情况,暂时无法对外提供服务。
那么,如何才能让 K8s 感知到业务真实的健康状态呢?这时候我们就需要用到 K8s 探针。
LivenessProbe 存活探针
用于判断容器是否健康,告诉 Kubelet 一个容器什么时候处于不健康的状态。如果 LivenessProbe 探针探测到容器不健康,则 Kubelet 将删除该容器,并根据容器的重启策略( Always、OnFailure 和 Never)做相应的处理
何时使用?
- 如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活态探针
- 如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活态探针
ReadinessProbe 就绪探针
用于判断容器是否启动完成且准备接收请求,如果探测失败,endpoint 将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址
何时使用?
- 如果你希望容器在探测失败时被杀死并重新启动,那么请指定一个存活态探针。这种情况和存活探针相同,就绪态探针的存在意味着 Pod 将在启动阶段不接收任何数据,并且只有在探针探测成功后才开始接收数据
- 如果你希望容器能够自行进入维护状态,也可以指定一个就绪态探针, 检查某个特定于就绪态的因此不同于存活态探测的端点
- 如果你的应用程序对后端服务有严格的依赖性,你可以同时实现存活态和就绪态探针。存活态探针检测通过后,就绪态探针会额外检查每个所需的后端服务是否可用
startupProbe 启动探针
指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器
何时使用?
- 对于所包含的容器需要较长时间才能启动就绪的 Pod 而言,启动探针是有用的
- 如果你的容器启动时间通常超出
initialDelaySeconds + failureThreshold × periodSeconds总值,你应该设置一个启动探测
探针的执行
三种探针的执行顺序主要可以分成三个阶段。
- 第一阶段:Pod 已启动,容器已启动,业务进程正在启动中,此时 StartupProbe 开始工作,由于 StartupProbe还未成功,当前 Pod 的容器处于 Not Ready(0/1) 的状态。
- 第二阶段:随着时间推移,StartupProbe 探针成功,Readine 和 Liveness 探针开始并行工作,此时由于 Readine 探针还未成功,当前 Pod 的容器仍然处于 Not Ready(0/1) 的状态。
- 第三阶段:随着 Readine 和 Liveness 的探测成功,当前 Pod 的容器转为 Ready(1/1) 的状态,Service EndPoints 将 Pod 加入到列表当中,Pod 开始接收外部请求。
- 轮询检测:每隔 10s 进行探针检测
实现方式
包含三种实现方式
- ExeAction:在容器中执行命令,返回0则健康
- TCPSocketAction:通过ip+port访问,如果可以被访问则健康
- HTTPGetAction:调用HTTP GET 方法,返回200-400则健康
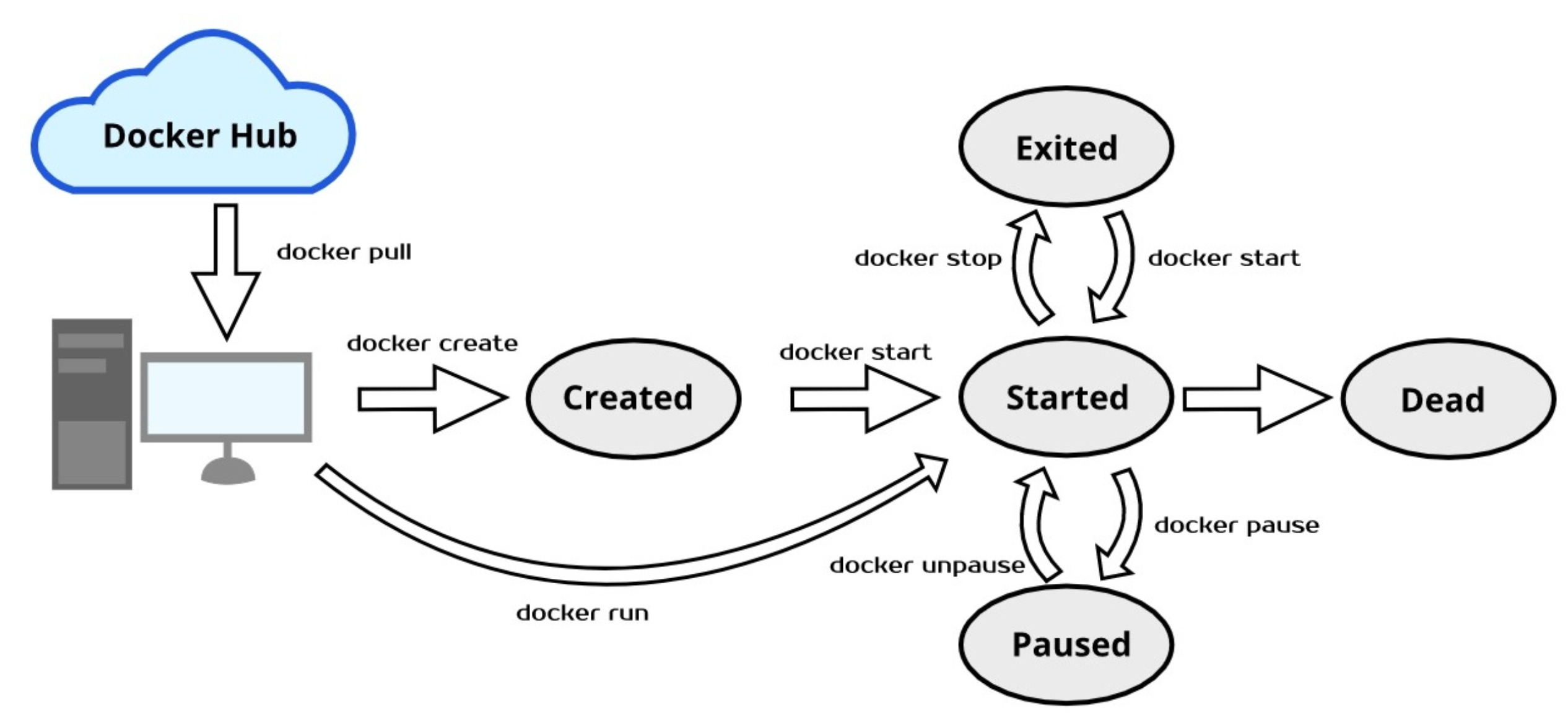
容器运行时 容器的生命周期?
https://blog.51cto.com/wzlinux/5063201
CRI 接口。containerd,docker,runc,rt
created(已创建),running(运行中),paused(暂停),exited(停止),dead(死亡)
iptables,ipvs实现负载均衡的区别?
iptables是Linux系统中的一个防火墙工具,它可以进行数据包过滤和转发。通过配置iptables规则,可以将请求从一个端口转发到多个后端服务器上,从而实现负载均衡
# 将所有来自外部IP的HTTP流量重定向到内部服务器群组
iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination 192.168.1.10:80
iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination 192.168.1.20:80
ipvs是一个高级的负载均衡工具,它在Linux内核中实现了一个虚拟服务器,可以将请求分发到多个后端服务器上。
- 与iptables相比,ipvs能够更有效地处理大量的并发连接,因为它是在内核层实现的,避免了用户空间和内核空间的切换。
- ipvs支持多种负载均衡算法,包括轮询、加权轮询、最少连接、加权最少连接等,可以根据实际需求选择合适的负载均衡算法。
# 加载ipvs内核模块
modprobe ip_vs
modprobe ip_vs_rr
modprobe ip_vs_wrr
modprobe ip_vs_sh
# 创建虚拟服务,将流量转发到后端服务器群组
ipvsadm -A -t 192.168.1.100:80 -s rr
ipvsadm -a -t 192.168.1.100:80 -r 192.168.1.10:80 -g
ipvsadm -a -t 192.168.1.100:80 -r 192.168.1.20:80 -g
iptables适用于简单的负载均衡场景,而ipvs适用于高性能和复杂的负载均衡场景
Endpoint 和 Iptables 的联系?
Service提供了虚拟IP,Endpoint记录了Service和Pod之间的映射关系,而iptables负责将请求转发到对应的Pod,从而实现了负载均衡和服务发现的功能。
详细的 Service 通过 iptables 将流量转发到 pod
创建一个ClusterIP类型的Service来暴露这个应用程序:
yamlCopy codeapiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
type: ClusterIP
上述配置创建了一个ClusterIP类型的Service,它会监听TCP端口80,并将请求转发给具有标签app: my-app的后端Pods的TCP端口8080。
接下来,Kubernetes会为这个Service创建一个虚拟IP地址,比如10.0.0.1。当集群内部的其他Pod或服务想要访问这个应用程序时,它们可以使用my-app-service这个名称来发起请求,而无需知道后端Pod的实际IP地址。
然后,Kubernetes会根据Service的选择器(app: my-app)来找到与之匹配的后端Pods。假设有3个后端Pods,它们的IP地址分别是10.1.0.1、10.1.0.2和10.1.0.3,且都监听着TCP端口8080。
此时,我们需要将这些后端Pods的IP地址和端口信息保存在一个名为Endpoint的Kubernetes资源中。Kubernetes会自动为我们创建和维护这个Endpoint资源,我们无需手动干预。
Endpoint是用于将Service与实际运行的Pods关联起来的对象。它提供了一种将Service的逻辑概念与实际运行的Pods的网络地址(IP地址和端口号)关联的机制。
当创建一个Service时,Kubernetes会自动创建对应的Endpoint。Endpoint的IP地址和端口号与Service关联的Pods的IP地址和端口号相同。当有新的Pod加入或旧的Pod移除时,Endpoint会相应地更新,以反映Service的实际后端Pods的状态。
Endpoint的定义可能如下所示:
yamlCopy codeapiVersion: v1
kind: Endpoints
metadata:
name: my-app-service
subsets:
- addresses:
- ip: 10.1.0.1
- ip: 10.1.0.2
- ip: 10.1.0.3
ports:
- port: 8080
上述配置定义了一个名为my-app-service的Endpoint资源,其中包含了三个后端Pod的IP地址和端口信息。
当有请求流量到达10.0.0.1:80(即my-app-service的ClusterIP和端口)时,Kubernetes会根据这个请求找到相应的Endpoint,然后将请求转发给其中的后端Pods(10.1.0.1:8080、10.1.0.2:8080和10.1.0.3:8080),从而实现负载均衡和请求转发的功能。
外部请求到内部pod的整个流程
DNS,Ingress,service,endpoint,kube-proxy,iptables,ipvs之间的关联,解析的整个过程
当客户端访问Pod服务时,涉及到的整个过程如下:
以一个示例来说明访问myapp-pod.default.svc.cluster.local域名的具体详细过程:
- 客户端发起一个HTTP请求,请求的目标域名是
myapp-pod.default.svc.cluster.local。 - 客户端的本地DNS解析器会首先查询本地缓存中是否有对应的域名解析结果。如果没有,它会向本地配置的DNS服务器发起请求。
- 本地DNS服务器会尝试解析
myapp-pod.default.svc.cluster.local域名。由于该域名是Kubernetes集群内部的域名,本地DNS服务器会将请求转发到Kubernetes内部的DNS服务器。 - Kubernetes内部的DNS服务器接收到请求后,会查询集群中的Service和Endpoint信息。它会查找名为
myapp-pod、命名空间为default的Service,并获取其对应的ClusterIP。 - 内部DNS服务器将
myapp-pod.default.svc.cluster.local域名解析为Service的ClusterIP,比如10.96.0.10。 - 现在客户端知道
myapp-pod.default.svc.cluster.local域名对应的ClusterIP是10.96.0.10,但这只是一个Kubernetes集群内部的IP地址。 - 外部负载均衡器(如云提供商的负载均衡器)将客户端的请求转发到Ingress控制器的外部IP地址,即
203.0.113.10。 - Ingress控制器接收到外部负载均衡器转发的请求,并根据配置的Ingress规则将请求转发到相应的后端Service或Pod上。
- Ingress控制器会根据Ingress规则将请求转发到名为
myapp-pod、命名空间为default的Service,通过DNS服务器将 service 域名解析成 service的ip,这个Service的ClusterIP是10.96.0.10。 - kube-proxy负载均衡(假设使用iptables):
- kube-proxy接收到来自Ingress的请求,并根据Service的Cluster IP地址(假设为
10.96.0.10)选择对应的后端Pod(这个是通过 endpoint 记录的) - iptables规则根据Service的Cluster IP地址
10.96.0.10将请求转发到后端Pod的IP地址(假设为192.168.1.2)和端口。
- kube-proxy接收到来自Ingress的请求,并根据Service的Cluster IP地址(假设为
- 最终,Service将请求转发到后端Pod的IP地址(假设为
192.168.1.2)和端口,完成整个访问过程。
总结起来,Kubernetes内部DNS负责将myapp-pod.default.svc.cluster.local域名解析为Service的ClusterIP,而外部负载均衡器负责将客户端的请求转发到Ingress控制器的外部IP地址,从而实现从外部访问Kubernetes集群内部的Service和Pod。
整个过程中涉及到的配置文件如下:
Pod的配置文件(pod.yaml):
yamlCopy codeapiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: myapp-image
ports:
- containerPort: 80
Service的配置文件(service.yaml):
yamlCopy codeapiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
Ingress的配置文件(ingress.yaml):
yamlCopy codeapiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-ingress
spec:
rules:
- host: myapp.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: myapp-service
port:
number: 80
iptables的负载均衡规则(假设转发到192.168.1.2):
iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination 192.168.1.2:80
使用 Ingress实现外部访问内部 service
为什么在Kubernetes中,除了使用Kubernetes内部DNS将域名解析到Service的ClusterIP外,还需要使用Ingress来实现从外部访问Service和Pod的需求。
Kubernetes内部DNS确实可以将myapp-pod.default.svc.cluster.local域名解析为Service的ClusterIP,这对于集群内部的服务发现和通信是非常有用的。通过ClusterIP,其他的Pod或Service可以直接访问该Service,而不需要暴露给外部。
然而,ClusterIP是一个集群内部的IP地址,无法从集群外部访问。如果我们希望将Kubernetes集群中的Service暴露给外部网络(例如公共互联网),就需要使用Ingress。
Ingress是一种Kubernetes资源,它充当了集群内Service和集群外部的通信桥梁。Ingress控制器是Kubernetes的一部分,负责监听Ingress资源的变化,并根据配置的规则将外部请求转发到相应的Service和Pod上。
Ingress具有以下优势:
- 外部访问: Ingress可以将集群内的Service暴露给外部网络,使得外部用户可以通过公共互联网访问这些Service。比如,你可以通过Ingress将
myapp-pod.default.svc.cluster.local域名映射到外部IP地址203.0.113.10,从而使得用户可以通过http://203.0.113.10来访问该Service。 - 主机和路径匹配: Ingress支持根据不同的主机名和URL路径来路由请求到不同的Service。这使得你可以在同一个集群中托管多个域名和多个应用,从而更灵活地管理和部署服务。
- SSL终止: Ingress可以处理SSL终止,将HTTPS请求解密后再转发到后端的Service和Pod上。这样,你可以通过Ingress实现HTTPS的终端加密,而无需在应用程序内部处理证书。
总结起来,虽然Kubernetes内部DNS可以解析Service的ClusterIP,但这仅适用于集群内部的服务发现和通信。要将服务暴露给外部网络,需要使用Ingress。Ingress通过监听外部的HTTP请求,并根据规则将请求转发到相应的Service和Pod上,实现了集群内部和外部的通信。
kube-dns,core-dns 的联系?
kube-dns,core-dns,dnsmasq 是可以混用,单独用,一起用?,他们之间的关联关系?
kube-dns,core-dns和dnsmasq是DNS解析相关的组件,它们在Kubernetes中可以单独使用或混用,但通常只会选择其中一个作为集群的DNS解析服务。
- kube-dns和core-dns都提供对Kubernetes内部服务名的DNS解析,可以将集群中的Pod和Service名称解析为对应的IP地址。
- core-dns相对于kube-dns更为灵活,可以支持更多的DNS解析配置,例如解析集群外部的域名,实现更复杂的DNS功能。
- dnsmasq在kube-dns中充当后端DNS解析器,为kube-dns提供本地DNS解析服务。
内部和外部域名解析的区别?
- 内部域名解析:
- 在Kubernetes集群内部,可以使用Service名称来解析到对应的Pod IP地址。这种解析方式通常用于集群内部通信,比如从一个Pod访问另一个Pod或Service。
- Kubernetes使用内部域名的格式为:
<service-name>.<namespace>.svc.cluster.local。
- 外部域名解析:
- 外部域名解析是指从Kubernetes集群外部访问集群中的服务。外部域名通常用于公网访问和跨集群通信。
- 外部域名解析不使用Kubernetes内部的DNS服务,而是通过公网DNS服务器解析。
pod内部访问 外部域名的流程?
当Pod内部访问外部域名时,流程如下:
- Pod内部发起DNS请求:
- Pod内部的应用程序发起DNS请求,要访问外部域名,如"example.com"。
- DNS解析:
- Pod内部的DNS解析器将"example.com"发送给集群节点上的kubelet。
- kubelet处理DNS请求:
- kubelet发现这是一个外部域名,它会将DNS请求发送给集群节点的主机上配置的DNS服务器。
- 主机上的DNS服务器解析:
- 主机上的DNS服务器接收到请求后,会向公网DNS服务器发送请求,进行外部域名的解析。
- 公网DNS服务器解析:
- 公网DNS服务器解析"example.com"并返回对应的IP地址给主机上的DNS服务器。
- DNS请求返回:
- 主机上的DNS服务器将解析结果返回给kubelet。
- kubelet将解析结果传递给Pod内部:
- kubelet收到解析结果后,将结果返回给Pod内部的应用程序。
- Pod内部应用程序访问外部域名:
- Pod内部应用程序可以使用解析得到的IP地址,通过网络访问外部域名"example.com"。
pod打散是如何实现的?
Pod的打散(Pod Disruption Budget)是一种用于保护应用程序高可用性的策略,它确保在一定时间内,不会因为Kubernetes集群的维护、节点故障或其他原因导致太多的Pod被同时终止。这样可以防止应用程序过度受到影响,从而提高系统的稳定性。
Pod的打散通过创建Pod Disruption Budget对象来实现。Pod Disruption Budget定义了一个最小的可用Pod数目(minAvailable)
假设有一个Deployment,其副本数为5,如果我们定义了Pod Disruption Budget为minAvailable: 2,那么在任何时刻,至少有2个Pod必须处于运行状态。如果有一个节点需要维护或故障,Kubernetes会确保在终止Pod之前先在其他节点上启动新的Pod,以保证最小可用Pod数不会降低。
Pod的打散可以在Deployment、StatefulSet等资源对象的规格中定义,以确保这些资源在维护期间具有所需的最小可用性。这样可以避免应用程序出现意外的中断或停机,提供更好的用户体验和高可用性。
service 暴露 后端服务的方式?
service的ClusterIP,NodePort,LoadBalancer 之间的区别?LoadBalance的负载均衡优势在哪里?
- ClusterIP:
- ClusterIP 是默认的 Service 类型。
- ClusterIP 为 Service 提供一个虚拟的 IP 地址,用于在集群内部进行服务之间的通信。
- ClusterIP 只能在集群内部访问,对外部不可见。
- 这种类型适用于需要在集群内部进行服务发现和通信的场景。
- NodePort:每个节点都会暴露 端口
- NodePort 是一种将 Service 暴露到集群节点上的类型。
- 它在 ClusterIP 的基础上,为 Service 提供了一个固定的端口(NodePort),允许外部通过节点的 IP 地址和 NodePort 来访问 Service。
- 外部请求会被负载均衡到后端的 Pod 上。
- 这种类型适用于需要从集群外部访问 Service 的场景,但不适合生产环境,因为 NodePort 端口范围有限制。
- LoadBalancer:只有一个节点暴露一个 端口
- LoadBalancer 是一种将 Service 暴露到云厂商提供的负载均衡器上的类型。
- 当使用云厂商提供的 Kubernetes 服务时(如 GKE、AKS、EKS 等),LoadBalancer 会自动创建云厂商的负载均衡器,并将外部请求负载均衡到后端的 Pod 上。
- 这种类型适用于需要在生产环境中,通过云厂商提供的负载均衡器实现外部流量访问 Service 的场景。
ClusterIP用于内部服务发现,NodePort提供外部访问的入口,LoadBalancer为外部客户端提供负载均衡和高可用性的服务访问方式。LoadBalancer类型的负载均衡优势在于自动分发流量,提高了服务的可靠性和性能。
- Service 负载均衡:
- 类型:Service 的负载均衡是基于四层(TCP/UDP)的负载均衡,根据请求的目标 IP 和端口进行负载均衡,不关心请求的内容。
- 范围:仅在 Kubernetes 集群内部有效,用于在集群内部将请求均匀地分发给后端的 Pod。
- 功能:主要用于在集群内部提供服务发现和负载均衡功能,确保多个 Pod 之间均匀地处理请求。
- LoadBalancer 负载均衡:
- 范围:适用于外部流量,可以将外部请求通过公网访问到 Kubernetes 集群中的 Service。
- 功能:主要用于将外部流量分发到 Kubernetes 集群中的 Service,可以实现外部流量的负载均衡和高可用性。
总的来说,Service 负载均衡主要用于集群内部的负载均衡,用于均衡地分发集群内部的请求给后端的 Pod,而 LoadBalancer 负载均衡主要用于将外部流量分发到集群内部的 Service,使外部请求能够访问到集群中的服务。两者可以结合使用,以实现全面的负载均衡和高可用性。
volume 和 PVC 的区别?
PVC(PersistentVolumeClaim,持久化存储卷声明)是Volume(存储卷)的一种类型,PVC用于请求持久化存储资源,而Volume用于提供容器之间或容器与宿主机之间共享数据的方法。
PVC是Volume的一种实现方式,用于满足持久化存储的需求,并通过请求相应的PV来将持久化存储资源与Pod绑定在一起。
Volume适用于临时性的、短暂的存储需求,而PVC适用于持久化的、长期的存储需求,并且可以在多个Pod之间共享。
PVC 存储资源在哪里?怎么创建的?
PVC(PersistentVolumeClaim)是Kubernetes中用于请求持久化存储资源的对象,它允许Pod通过声明性方式请求特定的存储资源。PVC并不是提前分配存储资源,而是在需要时向Kubernetes请求存储资源,并由Kubernetes根据预定义的存储类(StorageClass)来动态创建或绑定相应的PV(PersistentVolume)。
PV是集群中预先配置的存储资源,它可以是物理存储、网络存储或云存储等。PV可以由集群管理员提前配置并绑定到Kubernetes集群的某个存储后端。而PVC是Pod对PV的一种请求,它声明了希望使用的存储资源的要求,例如容量、访问模式等。
当PVC创建后,Kubernetes会根据PVC的定义,查找匹配的PV并绑定到该PVC上。如果没有合适的PV,根据PVC的storageClassName指定的StorageClass配置,Kubernetes会动态地创建一个PV,并将其绑定到PVC上。一旦PVC成功绑定到PV,Pod可以通过PVC来使用持久化存储资源。
storageclass 可以定义持久化存储的不同配置和属性,灵活切换配置
需要注意的是,PVC和PV都是Namespace级别的资源,因此它们在同一个Namespace中进行绑定。而且一个PVC只能绑定到一个PV上,而一个PV可以被多个PVC共享(多对一关系)。
metalLB 出现的原因?
metallb 相比于 云提供商的LoadBalance 是用来解决什么问题的?
并不是所有的Kubernetes部署都在云平台上,有些部署可能在裸机(Bare Metal)环境中,这时候就无法使用云平台提供的负载均衡器。MetalLB就是为了解决这个问题而生,它能够在裸机环境中提供类似云平台负载均衡器的功能。
MetalLB支持BGP协议,可以动态地从网络中获取空闲的IP地址,并分配给LoadBalancer
MetalLB支持多种负载均衡算法,这些算法可以根据实际需求选择,提供更加灵活和定制化的负载均衡策略。
Statefulset 和 Deployment的区别?
有状态的深入理解?
- 稳定的网络标识符:StatefulSet为每个Pod分配一个稳定的网络标识符(通常是一个DNS名称),使得在Pod重新启动或迁移时,其网络标识符保持不变。这样有状态的应用程序可以通过这个网络标识符来访问和处理数据,确保数据的一致性和可用性。
- 稳定的持久化存储:StatefulSet可以与持久化存储卷(Persistent Volume)结合使用,确保有状态的应用程序的数据持久性
- 有序的创建和删除:StatefulSet在创建或删除Pod时会按照顺序逐一完成,即先创建或删除第一个Pod,然后再创建或删除第二个Pod,以此类推。这样可以确保有状态的应用程序在进行扩容或缩容操作时,数据状态的正确转移和处理。
虽然Deployment也可以使用PVC来实现持久化存储,但它没有StatefulSet那样对持久化存储和Pod标识符的特殊要求
分享学习 k8s 的感受
对于某一点都要自己提出问题,然后去解决,对某些过程一定要十分的熟悉,多看官方文档,而不是博主总结的,可能会有一些误导的内容,或者因为版本更新导致的
主要就是k8s的学习,
-
做了一个 k8s的学习分享
-
包括k8s 的架构组件的基本原理,资源类型的深入理解
-
然后就是网络插件calico的学习
-
一些监控管理平台 kubesphere,prometheus,grafana的熟悉和使用
-
简单熟悉了一下云平台
接下来的计划是
- 继续深入理解k8s,对昨天的问题深入解决和理解
- 学习k8s 的规范和运维流程
- 二进制部署k8s集群
- 熟悉公司内部的k8s环境


评论区