



k8s | 监控 Prometheus + Grafana 简单使用(1)
Prometheus 是用 GO 语言开发的一个开源的系统监控和告警工具包,最初是 2012 年 SoundCloud 发布的,Prometheus是一个非常优秀的监控工具,准确的说,更是一套监控方案。Prometheus提供了监控数据收集,存储,处理可视化和告警的一套完整的监控解决方案。
-
github 地址:https://github.com/prometheus/prometheus
Grafana 是一个开源的跨平台的度量分析、可视化工具,支持多种数据源,如Prometheus、Elasticsearch、InfluxDB等。它提供了丰富的可视化图表和面板,可以帮助用户更好地理解和分析监控数据。
这一篇主要是关于 Prometheus 的原理和使用
架构 和 组件
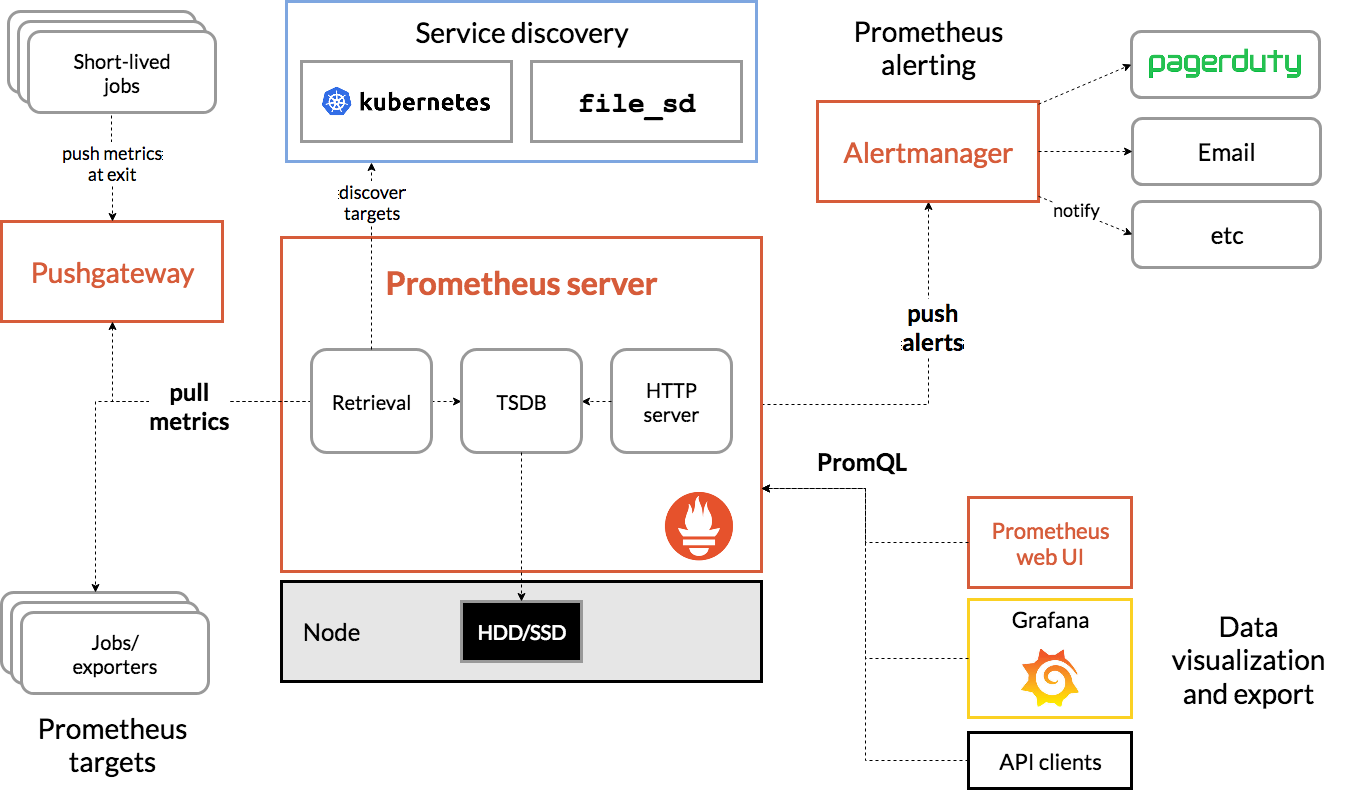
Prometheus Server
核心组件,负责数据的收集、存储和查询。Prometheus Server通过 HTTP 协议从Exporter或Pushgateway收集指标数据,Prometheus Server本身就是一个时序数据库(TSDB),将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。用户可以通过PromQL(Prometheus查询语言)来查询和分析存储的数据。
Exporter
Exporter是用于收集应用程序或服务的指标数据的组件, Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
Pushgateway
Pushgateway是一种临时的存储组件,用于接收短期工作的指标数据, Exporter可能无法直接暴露指标数据给Prometheus Server, 这时通过Pushgateway临时存储数据,然后由Prometheus Server定期从Pushgateway中拉取数据
Alertmanager
Alertmanager是用于处理警报的组件, 在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警
PromQL
PromQL是Prometheus的查询语言,用于查询和分析存储的指标数据。PromQL支持丰富的操作符和函数,可以进行数据聚合、过滤、计算等操作
工作流程
- Prometheus Server定期通过HTTP请求从Exporter或Pushgateway收集指标数据,并存储在本地的时间序列数据库中。
- 用户可以通过PromQL查询语言向Prometheus Server发送查询请求,Prometheus Server会从时间序列数据库中检索数据,并返回查询结果。
- Prometheus Server还可以根据配置的警报规则,对采集到的指标数据进行警报处理,并将警报发送给Alertmanager。
- Alertmanager负责对警报进行分组和去重,并根据配置的通知方式发送警报通知。
采集数据流程
Prometheus采集数据的步骤
- 定义监控指标: 想象一下,你的应用程序就像一个工厂,这个工厂有很多机器(服务器、数据库等)在工作。Prometheus想要监控这些机器的运行情况,比如温度(CPU使用率)、震动(磁盘I/O)等。为了做到这一点,每台机器都需要有一个仪表盘,显示这些信息。在Prometheus中,这些信息被称为“指标”。
- 暴露指标: 为了让Prometheus能够读取这些指标,每台机器都需要有一个特定的网址(通常是
/metrics),Prometheus可以访问这个网址来获取指标数据。这就像是机器上有一个屏幕,显示着所有Prometheus需要的信息。 - 配置Prometheus: Prometheus就像一个监控中心,它需要知道哪些机器(目标)需要监控,以及多久检查一次。这些信息都写在一个叫做
prometheus.yml的配置文件中。这个文件告诉Prometheus应该去哪些机器上读取数据,以及多久去读取一次。 - 定时拉取数据: Prometheus会按照配置的频率(比如每5分钟一次),去每台机器上访问那个特定的网址,获取最新的指标数据。这个过程就像是监控中心的工作人员定期去每台机器上抄表。
- 存储数据: 获取到的数据会被Prometheus保存在一个特殊的数据库中,这个数据库专门用来存储时间序列数据,就像是监控中心的档案室,记录着每台机器的历史数据。
- 查询和可视化: 当需要查看监控数据时,可以通过Prometheus的界面或者使用特殊的查询语言(PromQL)来查询数据库,获取想要的信息。这就像是在监控中心的大屏幕上显示数据。
- 设置告警: Prometheus还可以设置一些规则,比如如果机器的温度超过了某个值,就发出警报。这就像是监控中心有一个警报系统,如果检测到异常情况,就会提醒工作人员。
总结
Prometheus采集数据的过程就像是监控中心定期去每台机器上抄表,然后把这些数据保存起来,方便随时查看和分析。如果发现任何问题,它还可以发出警报,确保机器运行正常。这个过程是自动化的,不需要人工干预,Prometheus会一直默默地在后台工作,确保你的应用程序运行在最佳状态。
监控概念
数据模型
Prometheus 使用多维数据模型来表示指标数据。这个模型由指标名称和一组标签(label)组成,用于唯一标识一个时间序列。每个时间序列包含一系列的样本(sample),每个样本由一个时间戳和对应的值组成。
-
指标名称(Metrics Name)
代表了被监控的具体指标,比如 CPU 使用率、内存使用量、请求延迟等
-
标签(Label)
标签是用来区分不同时间序列的键值对。比如指标"cpu_usage",可以添加标签"instance"表示不同的节点或实例,也可以添加标签"job"表示不同的任务
-
样本(Samples)
样本是时间序列中的数据点,由一个时间戳和对应的值组成。时间戳表示数据点采集的时间,而值表示该时间点的指标数值
-
表现形式
Prometheus 使用一组时间序列的样本数据来表示监控指标,每个时间序列都由指标名称和一组标签组成。在查询时,可以使用 PromQL 查询语言来获取和处理这些时间序列数据
实例:两个指标"cpu_usage"和"memory_usage",对于"cpu_usage"指标,我们可以添加标签"instance"表示不同的节点,对于"memory_usage"指标,我们可以添加标签"job"表示不同的任务
以下是两个时间序列的样本数据:
cpu_usage{instance="node-1"}:
- (timestamp1, 0.85)
- (timestamp2, 0.90)
- (timestamp3, 0.70)
cpu_usage{instance="node-2"}:
- (timestamp1, 0.60)
- (timestamp2, 0.75)
- (timestamp3, 0.80)
memory_usage{job="app"}:
- (timestamp1, 256MB)
- (timestamp2, 512MB)
- (timestamp3, 128MB)
指标类型
-
Counter(计数器)
Counter 是一种单调递增的指标,用于表示累计的计数。如请求总数、错误总数等
-
Gauge (仪表盘)
Gauge 是一种可变的指标,用于表示某个瞬时的数值。通常用于表示系统状态的实时数值,如当前的 CPU 使用率、内存使用量等
-
Histogram(直方图)
Histogram 是一种用于测量和统计数据分布情况的指标,它会将数据按照指定的桶(bucket)范围进行划分,并计算每个桶中样本的数量。Histogram 可以用于统计请求的响应时间、请求大小等分布情况。
-
Summary(摘要)
Summary 是一种与 Histogram 类似的指标,用于测量数据分布情况。它会计算样本的分位数,比如50%分位数、90%分位数等,以及样本的总数。Summary 可以用于统计请求的响应时间等分布情况。
实例:包含了以下四个指标:
- Counter 类型的指标 “http_requests_total”,用于记录 HTTP 请求的总数。
- Gauge 类型的指标 “cpu_usage”,用于表示节点的 CPU 使用率。
- Histogram 类型的指标 “request_duration_seconds”,用于记录请求的处理时间分布情况。
- Summary 类型的指标 “response_size_bytes”,用于记录响应数据大小分布情况。
http_requests_total:
- (timestamp1, 100) # 在 timestamp1 时刻,请求总数为 100
- (timestamp2, 150) # 在 timestamp2 时刻,请求总数为 150
cpu_usage:
- (timestamp1, 0.85) # 在 timestamp1 时刻,节点的 CPU 使用率为 0.85
- (timestamp2, 0.90) # 在 timestamp2 时刻,节点的 CPU 使用率为 0.90
request_duration_seconds_bucket:
- (timestamp1, {"le": 0.1, "count": 10}) # 在 timestamp1 时刻,处理时间小于等于0.1秒的请求有 10 个
- (timestamp1, {"le": 1, "count": 50}) # 在 timestamp1 时刻,处理时间小于等于1秒的请求有 50 个
response_size_bytes_summary:
- (timestamp1, {"quantile": 0.5, "value": 1024}) # 在 timestamp1 时刻,50%的响应数据大小小于等于 1024 字节
- (timestamp1, {"quantile": 0.9, "value": 2048}) # 在 timestamp1 时刻,90%的响应数据大小小于等于 2048 字节
通过这些样例数据,我们可以使用 PromQL 查询语言来获取和分析 HTTP 请求总数、节点的 CPU 使用率、请求处理时间分布情况以及响应数据大小分布情况,从而对系统的性能和资源使用情况进行监控和分析。


评论区